 Apache SeaTunnel Committer | Zongwen Li
Apache SeaTunnel Committer | Zongwen Li
Introduction to Apache SeaTunnel
Apache SeaTunnel is a very easy-to-use ultra-high-performance distributed data integration platform that supports real-time synchronization of massive data.
Apache SeaTunnel will try its best to solve the problems that may be encountered in the process of mass data synchronization, such as data loss and duplication, task accumulation and delay, low throughput, etc.
Milestones of SeaTunnel
SeaTunnel, formerly known as Waterdrop, was open-sourced on GitHub in 2017.
In October 2021, the Waterdrop community joined the Apache incubator and changed its name to SeaTunnel.
SeaTunnel Growth


 When SeaTunnel entered the Apache incubator, the SeaTunnel community ushered in rapid growth.
When SeaTunnel entered the Apache incubator, the SeaTunnel community ushered in rapid growth.
As of now, the SeaTunnel community has a total of 151 contributors, 4314 Stars, and 804 forks.
Pain points of Existing engines
There are many pain points faced by the existing computing engines in the field of data integration, and we will talk about this first. The pain points usually lie in three directions:
- The fault tolerance ability of the engine;
- Difficulty in configuration, operation, and maintenance of engine jobs;
- The resource usage of the engine.
fault tolerance
Global Failover
 For distributed streaming processing systems, high throughput and low latency are often the most important requirements. At the same time, fault tolerance is also very important in distributed systems. For scenarios that require high correctness, the implementation of exactly once is often very important.
For distributed streaming processing systems, high throughput and low latency are often the most important requirements. At the same time, fault tolerance is also very important in distributed systems. For scenarios that require high correctness, the implementation of exactly once is often very important.
In a distributed streaming processing system, since the computing power, network, load, etc. of each node are different, the state of each node cannot be directly merged to obtain a true global state. To obtain consistent results, the distributed processing system needs to be resilient to node failure, that is, it can recover to consistent results when it fails.
Although it is claimed in their official blog that Spark’s Structured Streaming uses the Chandy-Lamport algorithm for Failover processing, it does not disclose more details.
Flink implemented Checkpoint as a fault-tolerant mechanism based on the above algorithm and published related papers: Lightweight Asynchronous Snapshots for Distributed Dataflows
In the current industrial implementation, when a job fails, all nodes of the job DAG need to failover, and the whole process will last for a long time, which will cause a lot of upstream data to accumulate.
Loss of Data
 The previous problem will cause a long-time recovery, and the business service may accept a certain degree of data delay.
The previous problem will cause a long-time recovery, and the business service may accept a certain degree of data delay.
In a worse case, a single sink node cannot be recovered for a long time, and the source data has a limited storage time, such as MySQL and Oracle log data, which will lead to data loss.
Configuration is cumbersome
Single table Configuration
 The previous examples are cases regarding a small number of tables, but in real business service development, we usually need to synchronize thousands of tables, which may be divided into databases and tables at the same time;
The previous examples are cases regarding a small number of tables, but in real business service development, we usually need to synchronize thousands of tables, which may be divided into databases and tables at the same time;
The status quo is that we need to configure each table, a large number of table synchronization takes a lot of time for users, and it is prone to problems such as field mapping errors, which are difficult to maintain.
Not supporting Schema Evolution
 Besides, according to the research report of Fivetran, 60% of the company’s schema will change every month, and 30% will change every week.
Besides, according to the research report of Fivetran, 60% of the company’s schema will change every month, and 30% will change every week.
However, none of the existing engines supports Schema Evolution. After changing the Schema each time, the user needs to reconfigure the entire link, which makes the maintenance of the job very cumbersome.
The high volume of resource usage
The database link takes up too much
 If our Source or Sink is of JDBC type, since the existing engine only supports one or more links per table, when there are many tables to be synchronized, more link resources will be occupied, which will bring a great burden to the database server.
If our Source or Sink is of JDBC type, since the existing engine only supports one or more links per table, when there are many tables to be synchronized, more link resources will be occupied, which will bring a great burden to the database server.
Operator pressure is uncontrollable
 In the existing engine, a buffer and other control operators are used to control the pressure, that is, the back pressure mechanism; since the back pressure is transmitted level by level, there will be pressure delay, and at the same time, the processing of data will not be smooth enough, increasing the GC time, fault-tolerant completion time, etc.
In the existing engine, a buffer and other control operators are used to control the pressure, that is, the back pressure mechanism; since the back pressure is transmitted level by level, there will be pressure delay, and at the same time, the processing of data will not be smooth enough, increasing the GC time, fault-tolerant completion time, etc.
Another case is that neither the source nor the sink has reached the maximum pressure, but the user still needs to control the synchronization rate to prevent too much impact on the source database or the target database, which cannot be controlled through the back pressure mechanism.
Architecture goals of Apache SeaTunnel Engine
To solve these severe issues faced by computing engines, we self-developed our engine expertise in big data integration.
Firstly, let’s get through what goals this engine wants to achieve.
Pipeline Failover
 In the data integration case, there is a possibility that a job can synchronize hundreds of sheets, and the failure of one node or one table will lead to the failure of all tables, which is too costly.
In the data integration case, there is a possibility that a job can synchronize hundreds of sheets, and the failure of one node or one table will lead to the failure of all tables, which is too costly.
We expect that unrelated Job Tasks will not affect each other during fault tolerance, so we call a vertex collection with upstream and downstream relationships a Pipeline, and a Job can consist of one or more pipelines.
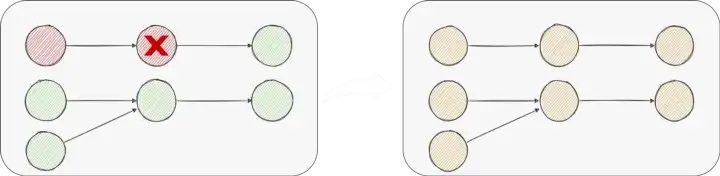
Regional Failover
Now if there is an exception in the pipeline, we still need to failover all the vertex in the pipeline; but can we restore only part of the vertex?
 For example, if the Source fails, the Sink does not need to restart. In the case of a single Source and multiple Sinks, if a single Sink fails, only the Sink and Source that failed will be restored; that is, only the node that failed and its upstream nodes will be restored.
For example, if the Source fails, the Sink does not need to restart. In the case of a single Source and multiple Sinks, if a single Sink fails, only the Sink and Source that failed will be restored; that is, only the node that failed and its upstream nodes will be restored.
Obviously, the stateless vertex does not need to be restarted, and since SeaTunnel is a data integration framework, we do not have aggregation state vertexes such as Agg and Count, so we only need to consider Sink;
- Sink does not support idempotence & 2PC; no restart and restart will result in the same data duplication, which can only be solved by Sink without restarting;
- Sink supports idempotence, but does not support 2PC: because it is idempotent writing, it does not matter whether the source reads data inconsistently every time, and it does not need to be restarted;
- Sink supports 2PC:
- If the Source supports data consistency, if an abort is not executed, the processed old data will be automatically ignored through the channel data ID, and at the same time, it will face the problem that the transaction session time may time out;
- If the Source does not support data consistency, perform abort on the Sink to discard the last data, which has the same effect as restarting but does not require initialization operations such as re-establishing links;
- That is, the simplest implementation is to execute abort. We use the pipeline as the minimum granularity for fault-tolerant management, and use the Chandy-Lamport algorithm to realize fault-tolerant distributed jobs.
Data Cache
 For sink failure, when data cannot be written, a possible solution is to work two jobs at the same time.
For sink failure, when data cannot be written, a possible solution is to work two jobs at the same time.
One job reads the database logs using the CDC source connector and then writes the data to Kafka using the Kafka Sink connector. Another job reads data from Kafka using the Kafka source connector and writes data to the destination using the destination sink connector.
This solution requires users to have a deep understanding of the underlying technology, and both tasks will increase the difficulty of operation and maintenance. Because every job needs JobMaster, it requires more resources.
Ideally, the user only knows that they will be reading data from the source and writing data to the sink, and at the same time, during this process, the data can be cached in case the sink fails. The sync engine needs to automatically add caching operations to the execution plan and ensure that the source still works in the event of a sink failure. In this process, the engine needs to ensure that the data written to the cache and read from the cache are transactional, to ensure data consistency.
Sharding & Multi-table Sync

For a large number of table synchronization, we expect that a single Source can support reading multiple structural tables, and then use the side stream output to keep consistent with a single table stream.
The advantage of this is that it can reduce the link occupation of the data source and improve the utilization rate of thread resources.
At the same time, in SeaTunnel Engine, these multiple tables will be regarded as a pipeline, which will increase the granularity of fault tolerance; there are trade-offs, and the user can choose how many tables a pipeline can pass through.
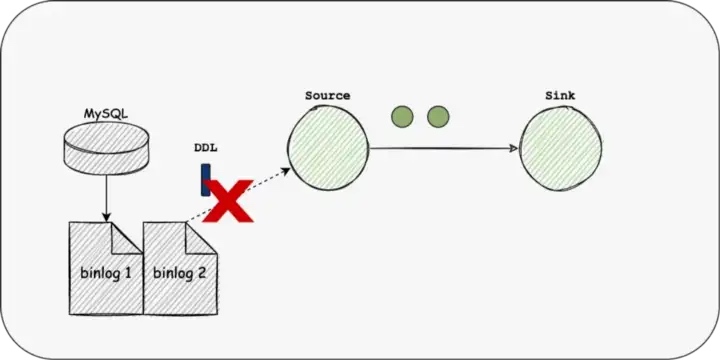
Schema Evolution
 Schema Evolution is a feature that allows users to easily change the current schema of a table to accommodate changing data over time. Most commonly, it is used when performing an append or overwrite operation, to automatically adjust the schema to include one or more new columns.
Schema Evolution is a feature that allows users to easily change the current schema of a table to accommodate changing data over time. Most commonly, it is used when performing an append or overwrite operation, to automatically adjust the schema to include one or more new columns.
This feature is required for real-time data warehouse scenarios. Currently, the Flink and Spark engines do not support this feature.
In SeaTunnel Engine, we will use the Chandy-Lamport algorithm to send DDL events, make them flow in the DAG graph and change the structure of each operator, and then synchronize them to the Sink.
Shared Resource
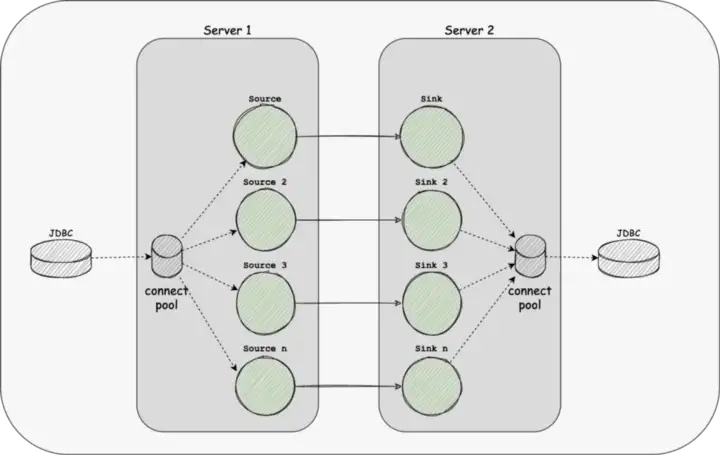 The Multi-table feature can reduce the use of some Source and Sink link resources. At the same time, we have implemented Dynamic Thread Resource Sharing in SeaTunnel Engine, reducing the resource usage of the engine on the server.
The Multi-table feature can reduce the use of some Source and Sink link resources. At the same time, we have implemented Dynamic Thread Resource Sharing in SeaTunnel Engine, reducing the resource usage of the engine on the server.
Speed Control
 As for the problems that cannot be solved by the back pressure mechanism, we will optimize the Buffer and Checkpoint mechanism:
As for the problems that cannot be solved by the back pressure mechanism, we will optimize the Buffer and Checkpoint mechanism:
- Firstly, We try to allow Buffer to control the amount of data in a period;
- Secondly, by the Checkpoint mechanism, the engine can lock the buffer after the Checkpoint reaches the maximum number of parallelism and executes an interval time, prohibiting the writing of Source data, achieving the result of taking the pressure proactively, avoiding issues like back pressure delay or failure to be delivered to Source. The above is the design goal of SeaTunnel Engine, hoping to help you better solve the problems that bother you in data integration. In the future, we will continue to optimize the experience of using SeaTunnel so that more people are willing to use it.
The future of Apache SeaTunnel
As an Apache incubator project, the Apache SeaTunnel community is developing rapidly. In the following community planning, we will focus on four directions:
Support more data integration scenarios (Apache SeaTunnel Engine) It is used to solve the pain points that existing engines cannot solve, such as the synchronization of the entire database, the synchronization of table structure changes, and the large granularity of task failure;
Guys who are interested in the engine can pay attention to this Umbrella: https://github.com/apache/incubator-seatunnel/issues/2272
Expand and improve Connector & Catalog ecology Support more Connector & Catalog, such as TiDB, Doris, Stripe, etc., and improve existing connectors, improve their usability and performance, etc.; Support CDC connector for real-time incremental synchronization scenarios.
Guys who are interested in connectors can pay attention to this Umbrella: https://github.com/apache/incubator-seatunnel/issues/1946
Support for more versions of the engines Such as Spark 3.x, Flink 1.14.x, etc.
Guys who are interested in supporting Spark 3.3 can pay attention to this PR: https://github.com/apache/incubator-seatunnel/pull/2574
Easier to use (Apache SeaTunnel Web) Provides a web interface to make operations more efficient in the form of DAG/SQL Simple and more intuitive display of Catalog, Connector, Job, etc.; Access to the scheduling platform to make task management easier
Guys who are interested in Web can pay attention to our Web sub-project: https://github.com/apache/incubator-seatunnel-web